
深浅模式
Collection
更新: 3/4/2026 字数: 0 字
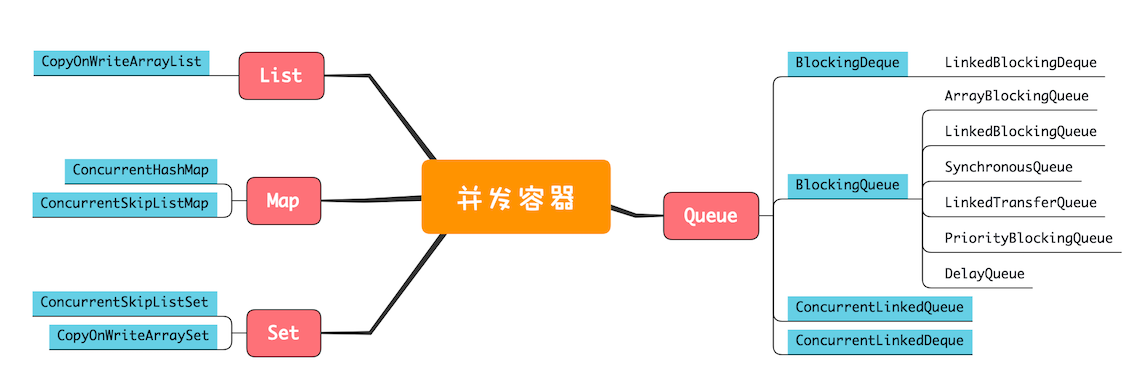
Java 中的容器主要可以分为四个大类,分别是 List、Map、Set 和 Queue,但并不是所有的 Java 容器都是线程安全的。
例如,我们常用的 ArrayList、HashMap 就不是线程安全的。
同步容器
Java 在 1.5 版本之前所谓的线程安全的容器,主要指的就是"同步容器"。不过同步容器有个最大的问题,那就是性能差,所有方法都用 synchronized 来保证互斥,串行度太高了。
下面的示例代码中,分别把 ArrayList、HashSet 和 HashMap 包装成了线程安全的 List、Set 和 Map:
java
List list = Collections.synchronizedList(new ArrayList());
Set set = Collections.synchronizedSet(new HashSet());
Map map = Collections.synchronizedMap(new HashMap());这些经过包装后线程安全容器,都是基于 synchronized 这个同步关键字实现的,所以也被称为"同步容器"。Java 提供的同步容器还有 Vector、Stack 和 Hashtable。
这三个容器不是基于包装类实现的,但同样是基于 synchronized 实现的,对这三个容器的遍历,同样要加锁保证互斥。
并发容器
因此 Java 在 1.5 及之后版本提供了性能更高的容器,我们一般称为"并发容器"。
并发容器虽然数量非常多,但依然是前面我们提到的四大类:List、Map、Set 和 Queue,下面的并发容器关系图,基本上把我们经常用的容器都覆盖到了。
List
List 是一种有序的容器类型,允许存储重复元素,通过索引访问元素。
基础 List 实现
常见实现对比
| List 类型 | 底层结构 | 是否线程安全 | 特点 | 适用场景 |
|---|---|---|---|---|
| ArrayList | 动态数组 | 否 | 随机访问快,中间插入删除慢 | 频繁随机访问,少量插入删除操作 |
| LinkedList | 双向链表 | 否 | 中间插入删除快,随机访问慢 | 频繁插入删除,少量随机访问操作 |
| Vector | 动态数组 | 是(synchronized) | 线程安全,性能较差 | 多线程环境,需要线程安全 |
基础实现详解
1. ArrayList
ArrayList 是基于动态数组实现的 List,具有以下特点:
- 随机访问:O(1) 时间复杂度,直接通过索引访问元素
- 插入删除:中间位置插入删除为 O(n) 时间复杂度,需要移动后续元素
- 扩容机制:初始容量 10,扩容时增加 50%
- 内存占用:紧凑,几乎只存储数据本身
java
List<String> list = new ArrayList<>();
list.add("element1"); // 尾部添加
list.get(0); // 随机访问
list.remove(0); // 移除元素2. LinkedList
LinkedList 是基于双向链表实现的 List,同时实现了 Deque 接口:
- 随机访问:O(n) 时间复杂度,需要遍历链表
- 插入删除:O(1) 时间复杂度,只需修改指针
- 内存占用:较高,每个元素需要额外存储两个指针
- 特点:支持双端操作,可作为栈或队列使用
java
List<String> list = new LinkedList<>();
list.add("element1"); // 尾部添加
list.get(0); // 需要遍历链表
list.remove(0); // 移除头部元素
// 作为双端队列使用
Deque<String> deque = new LinkedList<>();
deque.offerFirst("first");
deque.offerLast("last");3. Vector
Vector 是古老的线程安全的动态数组,具有以下特点:
- 线程安全:所有方法都使用 synchronized 修饰
- 扩容机制:初始容量 10,扩容时增加 100%
- 性能:由于同步开销,性能较差
- 建议:已不推荐使用,建议使用 Collections.synchronizedList(new ArrayList<>()) 代替
java
List<String> list = new Vector<>();
list.add("element1"); // 线程安全的添加操作基础 List 性能对比
数组和链表的性能对比
| 操作类型 | ArrayList (基于动态数组) | LinkedList (基于双向链表) |
|---|---|---|
| 随机访问 (get/set) | O(1) (极快) | O(n) (需要遍历) |
| 头部插入/删除 | O(n) (需要移动后续元素) | O(1) (仅需修改指针) |
| 尾部插入/删除 | O(1) (均摊复杂度) | O(1) |
| 中间插入/删除 | O(n) (移动元素是主要开销) | O(n) (寻址是主要开销) |
核心性能差异:缓存友好性
ArrayList(内存连续):由于底层是数组,所有元素在内存中是挨在一起的。当 CPU 加载数据时,会利用"局部性原理",一次性将一整块内存加载到 L1/L2 缓存中。这意味着当你遍历 ArrayList 时,下一个元素极大概率已经在缓存中了。
LinkedList(内存离散):每个节点(Node)都是独立分配的,分散在堆内存的各个角落。CPU 访问下一个节点时,必须根据指针去内存中"远距离"查找,这极易导致 Cache Miss(缓存失效)。
内存占用对比
| 特性 | ArrayList | LinkedList |
|---|---|---|
| 存储效率 | 高(几乎只存数据本身) | 低(每个数据都要额外存两个指针) |
| 内存布局 | 紧凑 | 碎片化 |
| 额外开销 | 数组末尾可能有空闲空间 | 严重,每个节点都是一个对象 |
注意:在 64 位 JVM 中,一个空的 LinkedList 节点本身就要占用约 24 字节,如果你只存一个 4 字节的 int,内存浪费率高达 600%。
基础 List 总结建议
99% 的场景请使用 ArrayList:
- 随机访问性能优异
- 内存占用低
- 遍历速度快
使用 LinkedList 的场景:
- 频繁在列表开头或中间插入/删除元素
- 不需要随机访问元素
- 不关心内存开销
实现栈或队列:
- 优先选择 ArrayDeque,性能优于 LinkedList
并发 List 实现
CopyOnWriteArrayList
CopyOnWriteArrayList 是并发包中提供的线程安全的 List 实现,基于"写时复制"原理:
- 读操作:完全无锁,直接读取内部数组
- 写操作:复制一份新数组,在新数组上修改,然后替换原数组
- 适用场景:读多写少的场景
- 特点:能够容忍读写的短暂不一致
实现原理
CopyOnWriteArrayList 内部维护了一个数组,成员变量 array 指向这个内部数组,所有的读操作都是基于 array 进行的:
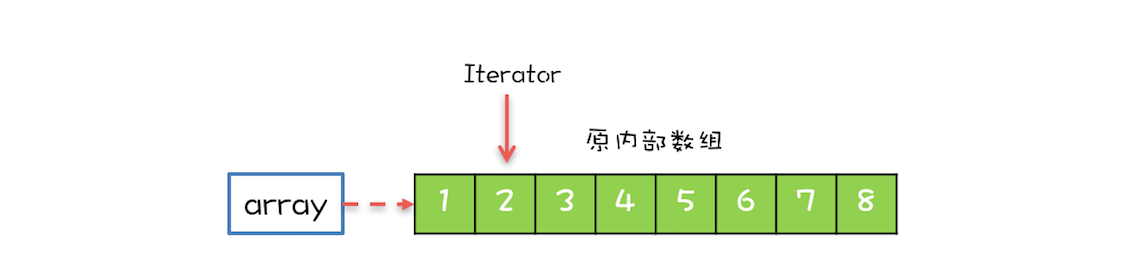
在遍历 array 的同时,还有一个写操作,例如增加元素,CopyOnWriteArrayList 会:
- 将 array 复制一份
- 在新复制的数组上执行增加元素的操作
- 执行完之后再将 array 指向这个新的数组
通过下图可以看到,读写是可以并行的:
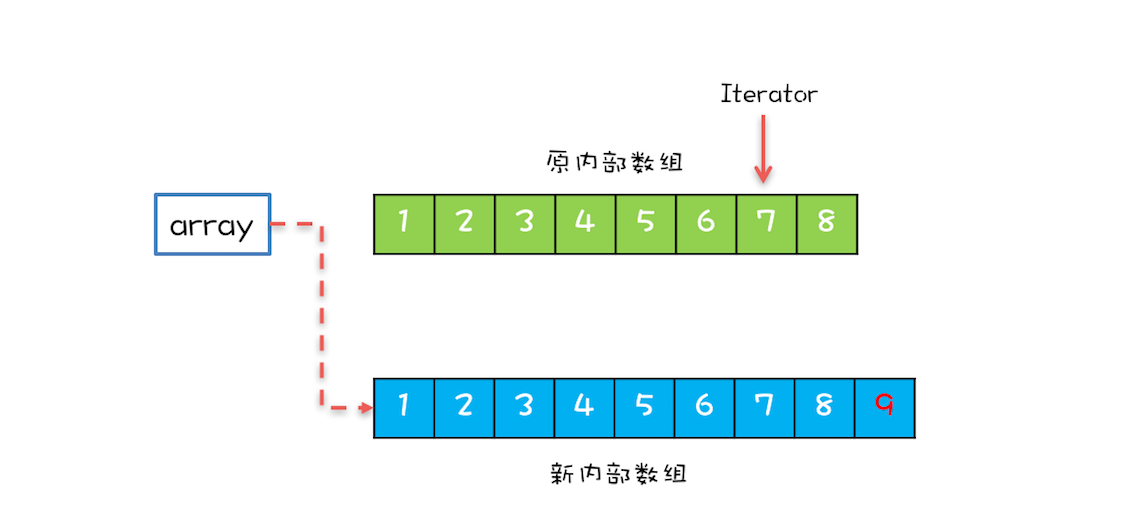
遍历操作一直都是基于原 array执行写操作则是基于新 array进行
注意事项
- 适用场景:仅适用于
写操作非常少的场景 - 读写一致性:写入的新元素并不能立刻被遍历到
- 迭代器:
CopyOnWriteArrayList的迭代器是只读的,不支持增删改,因为迭代器遍历的仅仅是一个快照
Map
Map 是一种键值对容器类型,通过键来存储和检索值,键不允许重复。
基础 Map 实现
常见实现对比
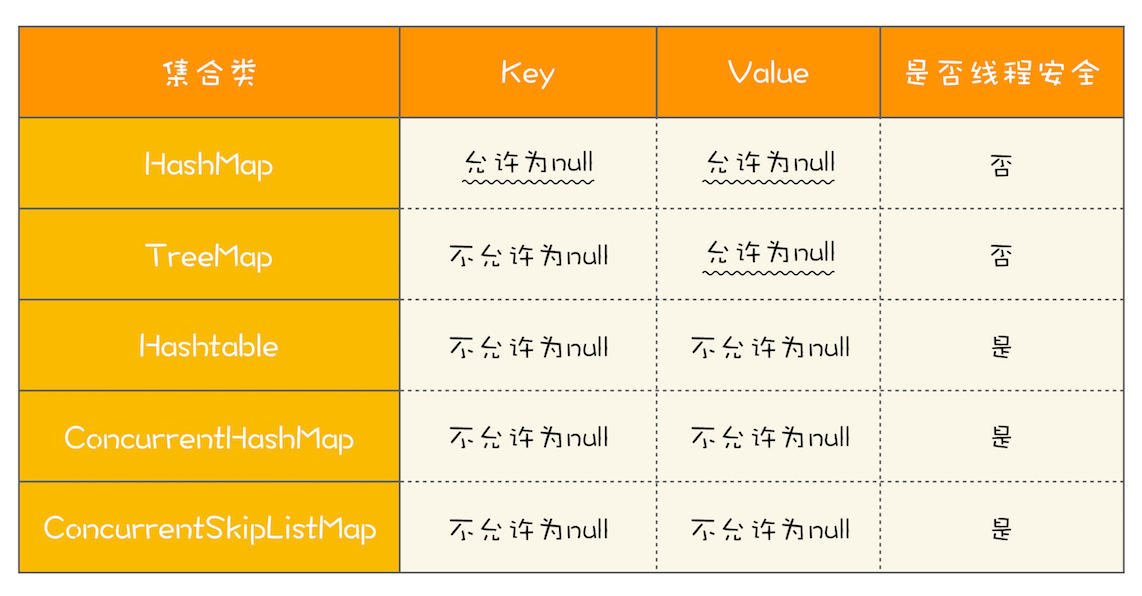
| Map 类型 | 底层结构 | 是否有序 | 排序方式 | 允许 null key | 查询性能 | 线程安全 |
|---|---|---|---|---|---|---|
| HashMap | 数组 + 链表/红黑树 | 否 | 无序 | 允许 1 个 | O(1) ~ O(logn) | 否 |
| LinkedHashMap | HashMap + 双向链表 | 是(插入/访问) | 插入/访问顺序 | 允许 1 个 | O(1) | 否 |
| TreeMap | 红黑树 | 是 | key 排序 | 不允许 | O(log n) | 否 |
| EnumMap | 数组(Enum.ordinal) | 是 | Enum 定义顺序 | 不允许 | O(1)(最快) | 否 |
| Hashtable | 数组 + 链表 | 否 | 无序 | 不允许 | O(1) ~ O(logn) | 是(synchronized) |
基础实现详解
1. HashMap
HashMap 是最常用的 Map 实现,基于数组 + 链表/红黑树实现:
- 底层结构:数组 + 链表(JDK 8 前),数组 + 链表/红黑树(JDK 8 后)
- 查询性能:平均 O(1),最坏 O(logn)(红黑树)
- 扩容机制:初始容量 16,负载因子 0.75,达到阈值时扩容为原来的 2 倍
- 树化条件:链表长度 >= 8 且数组长度 >= 64 时,链表转为红黑树
- 特点:允许 null key(只能有一个)和 null value
java
Map<String, Integer> map = new HashMap<>();
map.put("key1", 1); // 添加键值对
map.get("key1"); // 获取值
map.containsKey("key1"); // 检查键是否存在1.1 HashMap 整体结构总览
plaintext
HashMap
├── table: Node<K,V>[] // 核心数组(哈希桶),默认初始容量16,2的幂次
├── size: int // 实际存储的键值对数量
├── loadFactor: float // 负载因子(默认0.75)
├── threshold: int // 扩容阈值(capacity * loadFactor)
├── modCount: int // 结构修改次数(快速失败用)
└── TREEIFY_THRESHOLD: int = 8 // 链表转红黑树的阈值
UNTREEIFY_THRESHOLD: int = 6// 红黑树转回链表的阈值
MIN_TREEIFY_CAPACITY: int = 64 // 树化的最小数组容量1.2 HashMap 核心结构(数组 + 链表 + 红黑树)可视化
plaintext
┌───────────────────────────────────────────────────────────────────┐
│ HashMap 数组(table) │
│ 索引: 0 1 2 3 4 5 ... 15 │
│ ┌───┐ ┌───┐ ┌───┐ ┌───┐ ┌───┐ ┌───┐ ┌───┐
│ │null│ │Node│ │null│ │TreeNode│ │null│ │Node│ │null│
│ └───┘ └─┬─┘ └───┘ └───┬───┘ └───┘ └─┬─┘ └───┘
│ │ │ │
│ ▼ ▼ ▼
│ [11:val11] [3:val3] (红黑树根节点) [5:val5]
│ │ / \
│ ▼ [19:val19] [35:val35]
│ [27:val27] / / \
│ │ [51:val51] [67:val67] [83:val83]
│ ▼ / \
│ null [99:val99] [115:val115]
│ / \
│ null null
└───────────────────────────────────────────────────────────────────┘1.3 节点结构细分(Node vs TreeNode)
plaintext
// 1. 链表节点(Node)结构
Node<K,V>
├── hash: int // key的哈希值
├── key: K // 键
├── value: V // 值
└── next: Node<K,V> // 指向下一个链表节点(单向链表)
// 2. 红黑树节点(TreeNode,继承自Node)结构
TreeNode<K,V> extends Node<K,V>
├── 继承Node的hash/key/value/next
├── parent: TreeNode<K,V> // 父节点
├── left: TreeNode<K,V> // 左孩子
├── right: TreeNode<K,V> // 右孩子
├── prev: TreeNode<K,V> // 前驱节点(双向链表特性,方便遍历)
└── color: boolean // 颜色(红/黑,红黑树平衡用)2. LinkedHashMap
LinkedHashMap 继承自 HashMap,添加了双向链表来维护元素的顺序:
- 底层结构:HashMap + 双向链表
- 顺序:默认按插入顺序,可设置为访问顺序
- 查询性能:与 HashMap 相同,O(1)
- 特点:可以保持元素的插入顺序或访问顺序
- 适用场景:需要按顺序遍历元素的场景
java
// 按插入顺序
Map<String, Integer> map = new LinkedHashMap<>();
// 按访问顺序(最近访问的元素在末尾)
Map<String, Integer> accessOrderedMap = new LinkedHashMap<>(16, 0.75f, true);2.1 整体结构(继承 + 扩展)
plaintext
LinkedHashMap<K,V> extends HashMap<K,V> {
// 新增:双向链表的头节点(最早插入/访问的节点)
transient LinkedHashMap.Entry<K,V> head;
// 新增:双向链表的尾节点(最新插入/访问的节点)
transient LinkedHashMap.Entry<K,V> tail;
// 新增:排序模式(true=按访问顺序,false=按插入顺序,默认false)
final boolean accessOrder;
// 核心:自定义的 Entry 节点(继承 HashMap.Node,新增前后指针)
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before; // 前驱节点(双向链表)
Entry<K,V> after; // 后继节点(双向链表)
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
}2.2 核心结构可视化(数组 + 链表 + 红黑树 + 双向链表)
plaintext
// HashMap 底层数组(桶)
table (数组)
索引0: null
索引1: ┌─────────────────────────┐
│ LinkedHashMap.Entry(1) │ // 哈希桶中的节点
│ hash: xxx │
│ key:1, value:val1 │
│ next: null │ // 指向哈希冲突的下一个节点(无冲突则null)
│ before: Entry(3) │ // 双向链表前驱
│ after: Entry(5) │ // 双向链表后继
└─────────────────────────┘
索引2: null
索引3: ┌─────────────────────────┐
│ LinkedHashMap.Entry(3) │
│ hash: xxx │
│ key:3, value:val3 │
│ next: null │
│ before: null │ // 双向链表头节点,无前驱
│ after: Entry(1) │
└─────────────────────────┘
索引5: ┌─────────────────────────┐
│ LinkedHashMap.Entry(5) │
│ hash: xxx │
│ key:5, value:val5 │
│ next: null │
│ before: Entry(1) │
│ after: null │ // 双向链表尾节点,无后继
└─────────────────────────┘
// 独立的双向链表(维护顺序)
head → Entry(3) → Entry(1) → Entry(5) → tail
↑ ↓ ↑ ↓ ↑ ↓
← → ← → ← → (before/after 双向关联)3. TreeMap
TreeMap 基于红黑树实现,提供了有序的键值对:
- 底层结构:红黑树
- 顺序:按键的自然顺序或自定义比较器排序
- 查询性能:O(log n)
- 特点:不允许 null key,但允许 null value
- 适用场景:需要按键排序的场景
java
// 自然顺序排序
Map<String, Integer> map = new TreeMap<>();
// 自定义比较器
Map<String, Integer> customMap = new TreeMap<>((a, b) -> b.compareTo(a)); // 降序排序3.1 整体结构
plaintext
TreeMap
├── comparator: Comparator<? super K> // 比较器(决定key顺序)
├── entrySet: Set<Map.Entry<K,V>> // 键值对集合
├── size: int // 元素个数
└── root: Entry<K,V> // 红黑树根节点3.2红黑树节点结构(Entry)
plaintext
Entry<K,V>
├── key: K // 键(不可重复、可排序)
├── value: V // 值
├── left: Entry // 左孩子(比当前key小)
├── right: Entry // 右孩子(比当前key大)
├── parent: Entry // 父节点
└── color: boolean // 颜色(RED / BLACK)3.3 更完整的 “带指针” 结构(真实内存结构)
plaintext
[5-B]
/ | \
/ | \
left / |parent \ right
/ | \
[3-R] <------+------> [7-R]
/ \ / \
[2-B] [4-B] [6-B] [8-B]
/ \ / \ / \ / \
null null null null null null null null4. EnumMap
EnumMap 是专为枚举类型键设计的 Map 实现:
- 底层结构:数组(基于 Enum.ordinal())
- 查询性能:O(1),最快的 Map 实现
- 特点:键必须是枚举类型,不允许 null key
- 适用场景:使用枚举作为键的场景
java
enum Day { MONDAY, TUESDAY, WEDNESDAY }
Map<Day, String> map = new EnumMap<>(Day.class);
map.put(Day.MONDAY, "Monday");5. Hashtable
Hashtable 是古老的线程安全的 Map 实现:
- 底层结构:数组 + 链表
- 线程安全:所有方法都使用 synchronized 修饰
- 性能:由于同步开销,性能较差
- 特点:不允许 null key 和 null value
- 建议:已不推荐使用,建议使用 ConcurrentHashMap 代替
java
Map<String, Integer> map = new Hashtable<>();
map.put("key1", 1); // 线程安全的添加操作基础 Map 总结建议
一般场景:
- 优先使用 HashMap,性能优异
- 需要保持插入顺序或访问顺序时,使用 LinkedHashMap
- 需要按键排序时,使用 TreeMap
- 使用枚举作为键时,使用 EnumMap
线程安全场景:
- 高并发场景下,使用 ConcurrentHashMap
- 需要键有序的并发场景,使用 ConcurrentSkipListMap
并发 Map 实现
ConcurrentHashMap
ConcurrentHashMap 是并发包中提供的线程安全的 Map 实现,具有以下特点:
- 线程安全:基于分段锁(JDK 8 前)或 CAS + synchronized(JDK 8 后)实现
- 查询性能:接近 HashMap,O(1) 时间复杂度
- 并发度:支持高并发读写,读操作无锁
- 特点:不允许 null key 和 null value
- 适用场景:高并发场景下的 Map 操作
ConcurrentSkipListMap
ConcurrentSkipListMap 是基于跳表实现的线程安全的有序 Map:
- 底层结构:跳表(SkipList)
- 线程安全:基于 CAS 操作实现
- 查询性能:O(log n) 时间复杂度
- 特点:键有序,不允许 null key 和 null value
- 适用场景:需要键有序的高并发场景
跳表原理
跳表是一种有序的链表,但链表是单向的,跳表在链表的基础上增加了多级索引,通过索引来实现快速的查找:
- 插入、删除、查询操作:平均时间复杂度是 O(log n)
- 并发性能:理论上和并发线程数没有关系
- 特点:结构简单,查找速度快
1、整体结构
plaintext
ConcurrentSkipListMap
├── head: Node<K,V> // 跳表的头节点(所有层级的起点)
├── tail: Node<K,V> // 跳表的尾节点(哨兵节点)
├── size: LongAdder // 元素个数(并发安全计数)
└── 核心内部类:
├── Node<K,V> // 跳表的基础节点(存储key/value + 下一层节点)
├── Index<K,V> // 索引节点(包装Node,指向同层下一个Index + 下一层Index)
└── HeadIndex<K,V> // 头索引节点(继承Index,记录当前层级)2、核心节点结构

3、跳表完整结构可视化
plaintext
// HeadIndex(头节点,层级3)
HeadIndex(level=3) → null
↓ down
// Index层2(索引层)
Index(node=1) → Index(node=7) → null
↓ down ↓ down
// Index层1(索引层)
Index(node=1) → Index(node=3) → Index(node=7) → Index(node=9) → null
↓ down ↓ down ↓ down ↓ down
// Node层(原始层,完整链表)
Node(1) → Node(3) → Node(5) → Node(7) → Node(9) → Node(11) → null并发 Map 总结建议
一般并发场景:
- 优先使用 ConcurrentHashMap,性能优异
需要键有序的并发场景:
- 使用 ConcurrentSkipListMap
极高并发场景:
- 若对 ConcurrentHashMap 的性能还不满意,可以尝试 ConcurrentSkipListMap
Set
Set 接口的两个实现是 CopyOnWriteArraySet 和 ConcurrentSkipListSet。
使用场景可以参考前面讲述的 CopyOnWriteArrayList 和 ConcurrentSkipListMap。
它们的原理都是一样的,都是基于 CopyOnWriteArrayList 和 ConcurrentSkipListMap 实现的。
Queue
Queue 是一种先进先出(FIFO)的容器类型,主要用于存储和管理一组元素,支持在队尾插入元素,在队首移除元素。
基础 Queue 实现
常见实现对比
| Queue 类型 | 底层结构 | 是否阻塞 | 特点 | 适用场景 |
|---|---|---|---|---|
| LinkedList | 双向链表 | 非阻塞 | 实现了 Deque 接口,支持双端操作 | 一般队列操作,需要双端操作时 |
| ArrayDeque | 数组 | 非阻塞 | 基于循环数组实现,性能优于 LinkedList | 栈或队列操作,追求高性能时 |
| PriorityQueue | 堆 | 非阻塞 | 基于优先级排序,不保证 FIFO | 需要按照优先级处理元素时 |
基础实现详解
1. LinkedList 作为队列
LinkedList 实现了 Queue 和 Deque 接口,因此可以作为队列或双端队列使用:
java
// 作为队列使用
Queue<String> queue = new LinkedList<>();
queue.offer("element1"); // 入队
String element = queue.poll(); // 出队
// 作为双端队列使用
Deque<String> deque = new LinkedList<>();
deque.offerFirst("first"); // 队首入队
deque.offerLast("last"); // 队尾入队
String first = deque.pollFirst(); // 队首出队
String last = deque.pollLast(); // 队尾出队2. ArrayDeque
ArrayDeque 是基于循环数组实现的双端队列,性能优于 LinkedList,是实现栈和队列的首选:
- 优点:随机访问性能好,插入删除操作高效
- 缺点:容量固定,扩容时需要复制数组
java
// 作为栈使用
Deque<String> stack = new ArrayDeque<>();
stack.push("element1"); // 入栈
String element = stack.pop(); // 出栈
// 作为队列使用
Deque<String> queue = new ArrayDeque<>();
queue.offer("element1"); // 入队
String element = queue.poll(); // 出队3. PriorityQueue
PriorityQueue 是基于堆实现的优先级队列,元素按照自然顺序或自定义比较器排序:
- 特点:元素自动排序,不保证 FIFO
- 注意:不允许 null 元素,插入的元素必须可比较
java
// 自然顺序排序
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.offer(3);
pq.offer(1);
pq.offer(2);
System.out.println(pq.poll()); // 输出 1
// 自定义比较器
PriorityQueue<String> pq2 = new PriorityQueue<>((a, b) -> b.length() - a.length());
pq2.offer("apple");
pq2.offer("banana");
pq2.offer("cherry");
System.out.println(pq2.poll()); // 输出 banana基础 Queue 总结建议
一般场景:
- 如需双端操作,使用 LinkedList
- 如追求高性能,使用 ArrayDeque
优先级场景:
- 使用 PriorityQueue
性能考虑:
- 对于频繁的入队出队操作,ArrayDeque 性能最佳
- 对于需要双端操作的场景,LinkedList 更为灵活
并发 Queue 实现
Java 并发包里面 Queue 这类并发容器是最复杂的,你可以从以下两个维度来分类。
分类维度
一个维度是阻塞与非阻塞:
- 所谓阻塞指的是当队列已满时,入队操作阻塞
- 当队列已空时,出队操作阻塞
另一个维度是单端与双端:
- 单端指的是只能
队尾入队,队首出队 - 而双端指的是
队首队尾皆可入队出队
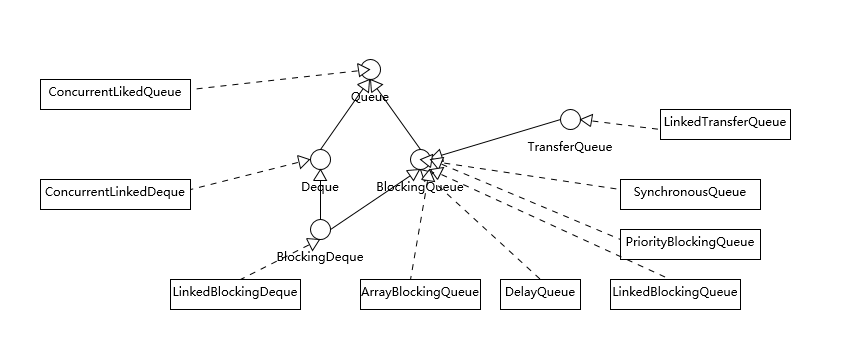
Java 并发包里阻塞队列都用 Blocking 关键字标识,单端队列使用 Queue 标识,双端队列使用 Deque 标识。
四大分类
这两个维度组合后,可以将 Queue 细分为四大类,分别是:
1. 单端阻塞队列
其实现有 ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、LinkedTransferQueue、PriorityBlockingQueue 和 DelayQueue。
- 内部一般会持有一个队列,这个队列可以是
数组(其实现是 ArrayBlockingQueue)也可以是链表(其实现是 LinkedBlockingQueue) - 甚至还可以
不持有队列(其实现是 SynchronousQueue),此时生产者线程的入队操作必须等待消费者线程的出队操作 - LinkedTransferQueue 融合 LinkedBlockingQueue 和 SynchronousQueue 的功能,性能比 LinkedBlockingQueue 更好
- PriorityBlockingQueue 支持按照优先级出队
- DelayQueue 支持延时出队
2. 双端阻塞队列
其实现是 LinkedBlockingDeque
3. 单端非阻塞队列
其实现是 ConcurrentLinkedQueue。
4. 双端非阻塞队列
其实现是 ConcurrentLinkedDeque。
对比
| 队列类型 | 底层数据结构 | 是否有界 | 锁实现(粒度) | 特点 | 使用场景 |
|---|---|---|---|---|---|
ConcurrentLinkedQueue | 链表 | ❌ 无界 | 非阻塞 (CAS + Wait-free) | 非阻塞队列;不实现 BlockingQueue 接口,不支持 put/take 阻塞操作 | 极高并发下的读写分离;不需要阻塞等待,只需快速存取的场景 |
| LinkedBlockingQueue | 链表 | ✅ 是(默认 MAX_VALUE) | 双锁(put/take 锁分离) | 吞吐量高于 ArrayBQ,但在高并发下可能产生大量 Node 对象 | 通用线程池(如 FixedThreadPool);IO 密集型任务 |
| ArrayBlockingQueue | 数组 | ✅ 是(强制固定) | 单锁(ReentrantLock,控制全队) | 内存连续、空间紧凑,但读写竞争同一把锁 | 固定大小任务队列;生产/消费速率平衡的场景 |
| PriorityBlockingQueue | 堆 | ❌ 无界 | 单锁(ReentrantLock) | 自动扩容;支持优先级排序(Comparable/Comparator) | 优先级任务调度;VIP 处理系统 |
| DelayQueue | 堆 | ❌ 无界 | 单锁(ReentrantLock) | 只有到期元素才能出队;基于 PriorityQueue 实现 | 缓存失效处理;订单超时自动取消;定时任务 |
| SynchronousQueue | 无(零容量) | ✅ 零容量 | 无锁(CAS + 队列/栈自旋) | 生产必须匹配消费,数据不存储直接移交 | 极高吞吐的任务移交;CachedThreadPool 默认配置 |
| LinkedTransferQueue | 链表 | ❌ 无界 | 无锁(CAS) | 结合了 LinkedBQ 和 SynchronousQueue 的特性,支持 transfer | 复杂的异步消息传递;高性能生产者消费者系统 |
LinkedBlockingDeque | 双向链表 | ✅ 是 | 双锁(put/take 锁分离) | 支持双端操作(FIFO/LIFO) | 任务窃取(Work-stealing)的变体;需要回滚或重试的任务 |
基础集合
List
引用关系
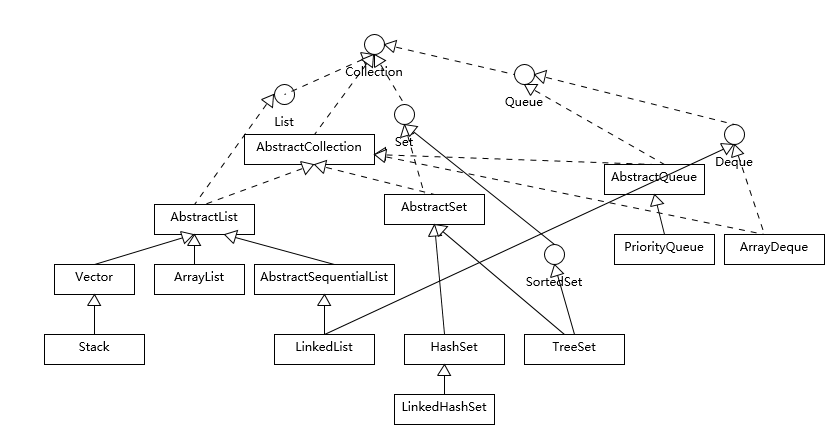
Vector、ArrayList、LinkedList
Vector:古老的线程安全的动态数组,实现了同步方法(synchronized),内部使用对象数组保存数据,自动增加容量(提高1倍),数组已满时,会创建新的数组,并拷贝原有数组;
- a) 已不推荐使用,建议用 Collections.synchronizedList(new ArrayList<>()) 代替;
ArrayList:非线程安全的动态数组,和Vector近似,初始容量 10,扩容时增加50%;
- a) 可以通过 Collections.synchronizedList() 包装为线程安全
LinkedList:是双向链表,不需要调整容量,也不是线程安全的;
- a) 实现了 Deque 接口,支持当作栈或队列使用;
动态数组适合随机访问的场合,除了尾部插入和删除元素,中间插入性能较差,会移动后续所有元素;
双向链表进行节点插入和删除高效很多,但是随机访问的性能比动态数组慢;
数组和链表的性能对比
| 操作类型 | ArrayList (基于动态数组) | LinkedList (基于双向链表) |
|---|---|---|
| 随机访问 (get/set) | O(1) (极快) | O(n) (需要遍历) |
| 头部插入/删除 | O(n) (需要移动后续元素) | O(1) (仅需修改指针) |
| 尾部插入/删除 | O(1) (均摊复杂度) | O(1) |
| 中间插入/删除 | O(n) (移动元素是主要开销) | O(n) (寻址是主要开销) |
核心性能差异:缓存友好性
这是两者最本质的区别:
ArrayList(内存连续):由于底层是数组,所有元素在内存中是挨在一起的。当 CPU 加载数据时,会利用"局部性原理",一次性将一整块内存加载到 L1/L2 缓存中。这意味着当你遍历 ArrayList 时,下一个元素极大概率已经在缓存中了。
LinkedList(内存离散):每个节点(Node)都是独立分配的,分散在堆内存的各个角落。CPU 访问下一个节点时,必须根据指针去内存中"远距离"查找,这极易导致 Cache Miss(缓存失效)。
写入性能的"反直觉"表现
虽然理论上 LinkedList 插入是 O(1),但实际情况如下:
中间插入
ArrayList:需要调用 System.arraycopy() 移动元素。虽然是
O(n),但这是底层 C++ 实现的内存批量拷贝,在元素量不是巨大的情况下(如几千个),速度极快。LinkedList:虽然修改指针是
O(1),但它必须先遍历寻址到那个位置,这个O(n)的寻址过程(多次内存随机跳转)通常比ArrayList 的内存拷贝还要慢。
尾部追加 (Add)
ArrayList:绝大多数情况是直接在数组末尾写入。只有在扩容时会变慢。
LinkedList:每次 add 都要创建一个新的 Node 对象。创建对象和垃圾回收(GC)的开销远大于数组赋值。
内存占用对比
| 特性 | ArrayList | LinkedList |
|---|---|---|
| 存储效率 | 高(几乎只存数据本身) | 低(每个数据都要额外存两个指针) |
| 内存布局 | 紧凑 | 碎片化 |
| 额外开销 | 数组末尾可能有空闲空间 | 严重,每个节点都是一个对象 |
注意:在 64 位 JVM 中,一个空的 LinkedList 节点本身就要占用约 24 字节,如果你只存一个 4 字节的 int,内存浪费率高达 600%。
实际基准测试结论 (JMH)
根据典型的 Java 基准测试结果:
- 顺序遍历:ArrayList 比 LinkedList 快 10 倍以上。
- 随机访问:ArrayList 完胜。
- 尾部插入:ArrayList 更好,因为它不需要频繁创建对象。
只有一种情况 LinkedList 占优:在列表头部进行极大规模的插入操作(如 add(0, item))。但如果你有这种需求,通常应该使用 ArrayDeque。
总结建议
99% 的场景请使用 ArrayList。
只有当你明确需要频繁在列表开头插入/删除元素,且不关心内存开销和随机访问速度时,才考虑 LinkedList。
如果你需要实现栈(Stack)或队列(Queue),优先选择 ArrayDeque,它的性能在大多数场景下也优于 LinkedList。
Map
Map 是最常见的容器类型,以键值对的形式存储和操作数据。
引用关系
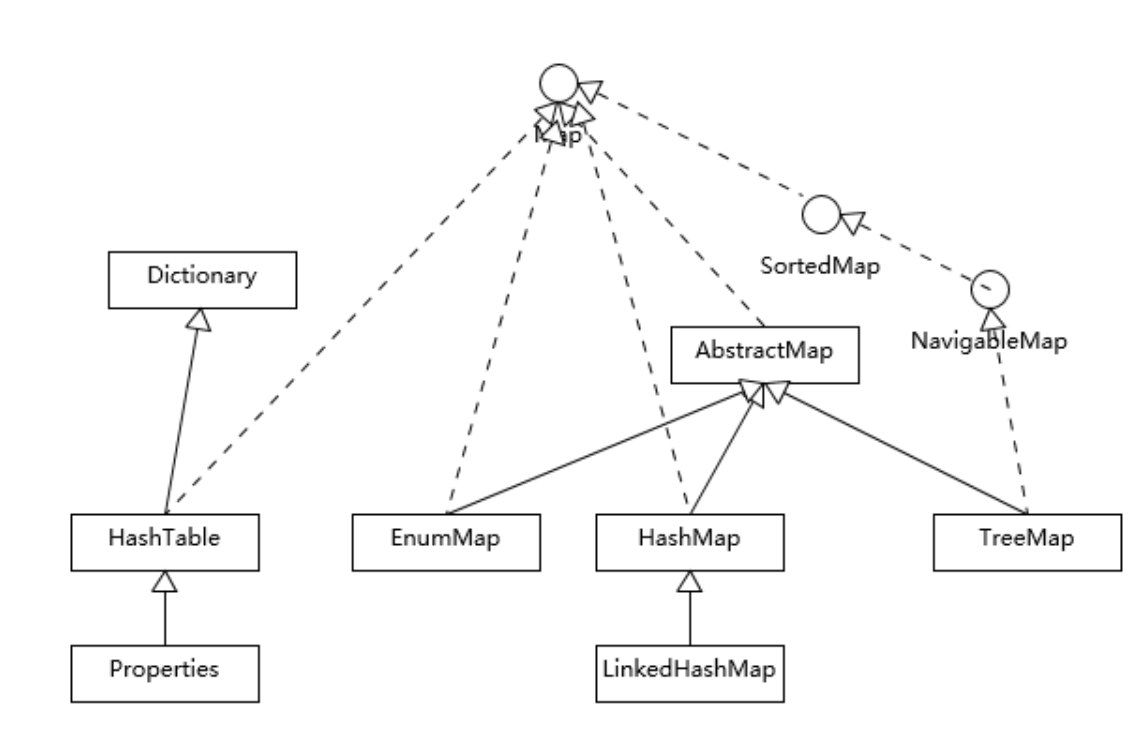
常见 Map 实现对比
| Map 类型 | 底层结构 | 是否有序 | 排序方式 | 允许 null key | 查询性能 | 线程安全 |
|---|---|---|---|---|---|---|
| HashMap | 数组 + 链表/红黑树 | 否 | 无序 | 允许 1 个 | O(1) ~ O(logn) | 否 |
| LinkedHashMap | HashMap + 双向链表 | 是(插入/访问) | 插入/访问顺序 | 允许 1 个 | O(1) | 否 |
| TreeMap | 红黑树 | 是 | key 排序 | 不允许 | O(log n) | 否 |
| EnumMap | 数组(Enum.ordinal) | 是 | Enum 定义顺序 | 不允许 | O(1)(最快) | 否 |
HashMap 详解
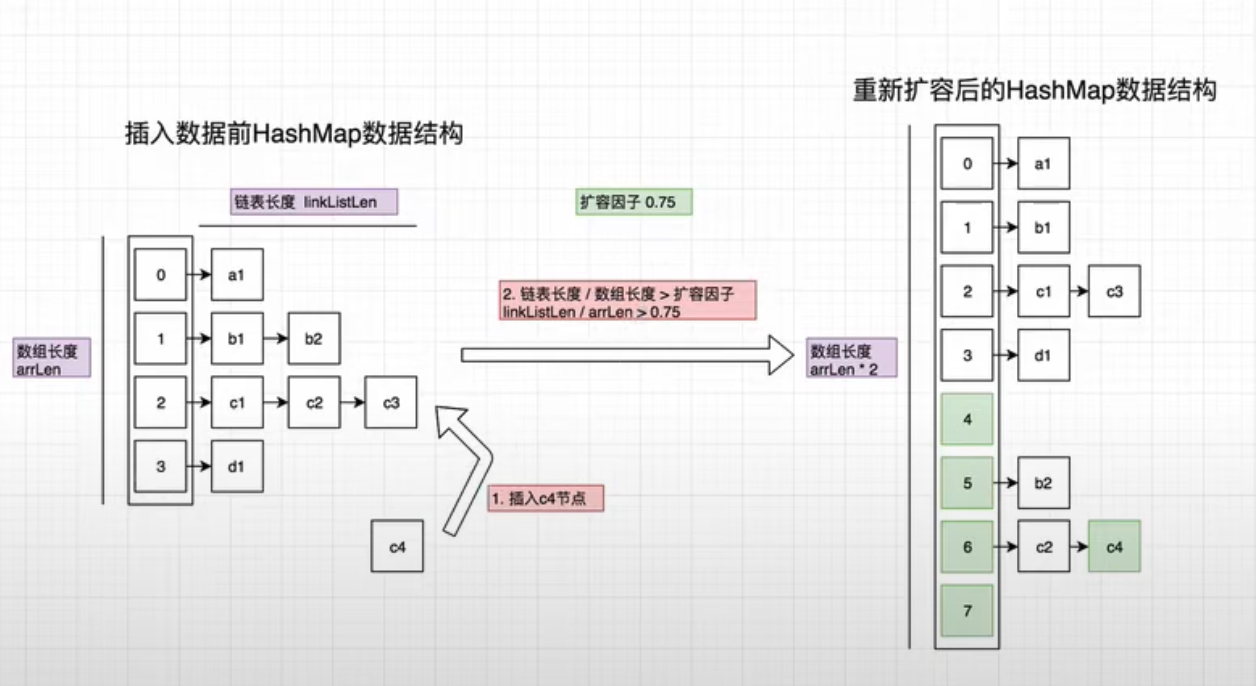
1. 扩容机制
当数组空间达到 75% 时,数组长度会扩大为原来的 2 倍,并重新计算下标。
java
// 默认初始容量,必须是2的幂。初始数组长度(实际是桶数组大小)
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 如果隐式指定了更高的值,则使用最大容量, 必须是2的幂 <= 1<<30
static final int MAXIMUM_CAPACITY = 1 << 30; // aka 1073741824
// 默认负载系数
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 单个桶链表长度超过8转为红黑树
static final int TREEIFY_THRESHOLD = 8;
// 单个桶红黑树长度小于6转为链表
static final int UNTREEIFY_THRESHOLD = 6;
// 最小树化阈值,HashMap 中的数组长度(即桶数组 table 的长度,也指的容量)超过该值,才会进行树化(为了防止前期阶段频繁扩容和树化过程冲突)
static final int MIN_TREEIFY_CAPACITY = 64;- capacity [容量] = 16
- loadFactor [负载系数] = 0.75
- threshold [阈值] = 16 * 0.75 = 12
扩容条件:当元素数量(键值对) >= 12 时,触发扩容,并执行 2 倍扩容(新的 capacity = 旧 capacity * 2)。
树化触发条件:链表长度 ≥ 8 且 数组长度 ≥ 64。
2. 红黑树
红黑树是一种高效的检索二叉树,在 JDK 8 中:
- 当数组长度 ≥ 64 且链表长度大于 8 时,链表会转换成红黑树
- 当红黑树长度小于 6 时,会转回链表
3. HashMap 死循环
死循环 发生在 JDK 1.8 之前的版本中,是指在并发环境下,因为多个线程同时进行 put 操作,导致链表形成环形数据结构,一旦形成环形数据结构,在 get(key) 的时候就会产生死循环。
原因 是由以下条件共同导致的:
- HashMap 使用头插法进行数据插入(JDK 1.8 之前)
- 多线程同时添加元素
- 触发了 HashMap 扩容